思い立って本の電子書籍化をすることにしました。
前回は準備についての記事を書きましたが、すべての道具がそろったので裁断とスキャンをしてみます。
まずは本を裁断
まずは本を裁断していきます。裁断に使う道具はこちら:

詳細は以下の記事をご覧ください。
予想外だったのは、マットが結構ゴム臭いことくらいでした。
電子書籍化の実験に使うのはこちらの本です:

江國香織さんの「流しの下の骨」です。この本は何度も何度も読んでボロボロになっています。ボロボロになりすぎたのでハードカバー版を別に買ってしまったほどです。
本好きとしては本を切り刻みたくはないのですが、世のため人のため断捨離のために犠牲になってもらいます。
1.カバー表紙を裁断

まずはカバーを外し、表紙を裁断します。気持ちの問題で、表紙をつけておこうと思ったためですが、いらなければやる必要はありません。
といっても1枚だけなので簡単です。定規を当ててロータリーカッターを滑らせます。下にはマットをひくのを忘れずに。
2.本を裁断

次に本自体を裁断します。
本の背表紙ぎりぎりに定規を当て、それに沿わせてロータリーカッターを前後に動かします。
ぎりぎりといってもあまりに追い込みすぎるとミスをするので、適当で大丈夫です。
単に滑らせれば少しずつ切れていくのかと思っていましたが、ある程度の厚みがあると力を下に入れて滑らせないと切れなかったです。
また、歯の厚みの分しか一度に切れないので、ある程度切ったら切れたページを外して再開することが必要です。

裁断が完了するとこんな感じになります。左がページごとに分かれた本、右の白い棒状のものが背表紙です。
結構切りくずが出るので掃除をしっかりした方がいいかもしれません。
本をスキャン
裁断が終わったら本をスキャンしていきます。使うのはブラザーのDCP-J963Nです。

以前の記事でも書きましたが、安価なインクジェットプリンター複合機で原稿を連続してスキャンできるADFがついているのはこれくらいでした。「できるだけ安く」がコンセプトなのでドキュメントスキャナは使いません。
1.本をADFにセット
このDCP-J963N、ADFがついているのはいいのですが、残念ながら両面読み取りができません。
したがって、各ページの表(奇数ページ)と裏(偶数ページ)をわけてスキャンする必要があります。
さらに、何百ページにもなる本を一度にスキャンすることは不可能ですので、分割してスキャンする必要があります。それらを後から結合する必要がありますがそれはまた後程。

こんな感じでADFにセットします。文庫本を縦にセットしようとすると、グレーの紙押さえがそこまで小さくならないので、うまくいきません。横向きならうまくセットすることができました。

スキャンするとこんな感じで出てきます。ここで非常に重要な注意ですが、左側のカバーを開けた状態でスキャンしては絶対にダメです。上の写真ではわかりやすさのために開けていますが、開けた状態でスキャンするとほぼ100%紙詰まりになり、さらに取り出すときに本が破ける可能性が高いです。
文庫本を横向きにセットしている都合上、スキャンの終わったページを取り出す際に左側のカバーを開ける必要があります。が、そのあとで閉めるのを忘れて次のページをスキャンしてしまったことが何度もあり、そのたびに悲しい思いをしました。。。
2.パソコンからスキャン
スキャンにはこの複合機についている “Prest! PageManager” というソフトを使います。
このソフト、無料でついてくる割に高機能で、スキャンした文字を認識するOCR機能もついています。
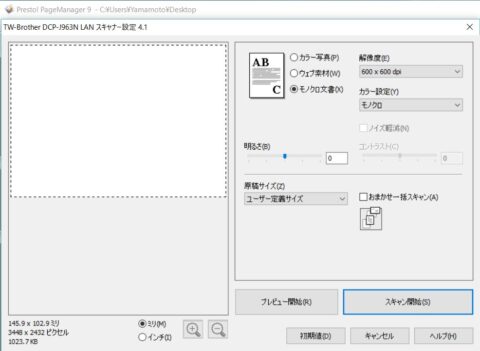
スキャンを実行するとこんな画面が出てきます。今回はモノクロの本をスキャンするので「モノクロ文書」にしています。表紙をスキャンするときは「カラー写真」とかにした方がいいかと思います。
解像度設定
解像度の設定はOCRを使用する際は300x300dpi以上にした方がいいそうです。が、600x600dpiにセットするとやたらとスキャンが遅くなります。
300x300dpiでも十分OCRで認識してくれましたので300x300dpiで実行します。
原稿のサイズ
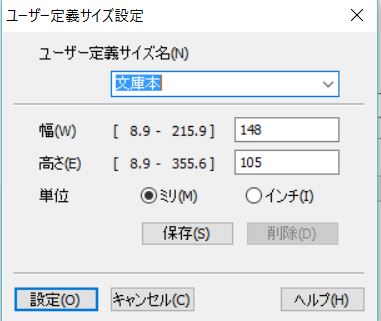
「原稿のサイズ」はユーザー定義にする必要があります。
今回の文庫本は148x105mmだったのでそのように設定します:
ひたすらスキャン
設定で来たらあとはひたすらスキャンします。
なお、この複合機(J963N)にはADFでの両面スキャンがないので、裏面もスキャンするのを忘れずに。
また、何百ページもある本を一度にスキャンできるほどADFが厚くないので、数10ページごとに分ける必要があります。
スキャンができたらOCRにかけPDF化
スキャンができたらそれぞれをOCRにかけ、PDF化しておきます。
OCR化はPresto! PageManager 9で可能です。
これで、1, 3, 5, 7,…,19という奇数ページだけ集まったものと、20,18,16,…,2という偶数ページだけ集まったものが出来上がります。ページを分割してスキャンしているはずなので、21,23,25…とか40,38,…というのとかもできているはずです。
偶数ページが逆になるのは、裁断すると偶数ページは裏面になるので、そのままスキャンすると逆順になるためです。あとから結合する際に戻せるので問題ありません。
とにかくカバーを開けた状態でスキャンしないように注意!
繰り返しになりますが、絶対に左側のカバーを開けた状態でスキャンしないようにしてください!!
長くなったので奇数/偶数ページの結合はまた次回: